About this doc:
- 初学 kafka 时的笔记记录
- 系统地学完 kafka 后梳理出脑图
- 结合实战 (工作中使用 Spring Kafka) 给出实战中的内容
- 让别人能够看懂这份手册,并用于自己时常翻看
- 不断优化这份笔记,使其脉络清晰,简单易懂并可用性高。
本次学习 kafka ,目标有三个,若不能全部完成就不能说本次学习是成功的或者说是完成了:
- 学习 Java 客户端 对 kafka 的使用及调参,本文立足于 Java 开发工程师,使用 Spring-Kafka 封装好的 kafka 客户端。
- 学习 kafka 的原理。
- 搭建及管理 kafka 线上环境,主要是指监测 kafka 集群情况。
在本人学习本文档时参考的文章名称或链接将贴在文末,文中也会引用这些文章中的精华部分。
一、Kafka 基础
1.1 Kafka 与 消息引擎
kafka 有时也被称为消息中间件或者消息队列,但这二者都不是特别合适,消息引擎更能体现出 kafka 在实际应用中所担任的角色与作用。
消息引擎系统定义:
维基百科:消息引擎系统是一组规范。企业利用这组规范在不同系统之间传递语义准确的消息,实现松耦合的异步式数据传递。
简单理解:系统 A 发送消息给消息引擎系统,系统 B 从消息引擎系统中读取 A 发送的消息。
Java Message Service:
提到消息引擎系统,你可能会问 JMS 和它是什么关系。JMS 是 Java Message Service,它也是支持上面这两种消息引擎模型的。严格来说它并非传输协议而仅仅是一组 API 罢了。不过可能是 JMS 太有名气以至于很多主流消息引擎系统都支持 JMS 规范,比如 ActiveMQ、RabbitMQ、IBM 的 WebSphere MQ 和 Apache Kafka。当然 Kafka 并未完全遵照 JMS 规范,相反,它另辟蹊径,探索出了一条特有的道路。
为什么系统 A 不能直接发送消息给系统 B,中间还要隔一个消息引擎呢?答案就是 “削峰填谷”。这四个字简直比消息引擎本身还要有名气。
所谓的“削峰填谷”就是指缓冲上下游瞬时突发流量,使其更平滑。特别是对于那种发送能力很强的上游系统,如果没有消息引擎的保护,“脆弱”的下游系统可能会直接被压垮导致全链路服务“雪崩”。但是,一旦有了消息引擎,它能够有效地对抗上游的流量冲击,真正做到将上游的“峰”填满到“谷”中,避免了流量的震荡。
Kafka 能够有效隔离上下游业务,将上游突增的流量缓存起来,以平滑的方式传导到下游子系统中,避免了流量的不规则冲击。
消息引擎系统的另一大好处在于发送方和接收方的松耦合,这也在一定程度上简化了应用的开发,减少了系统间不必要的交互。
Kafka 自然有它的优势所在,不过多了一个环节就会带来一些新的问题,这些问题的产生大多数是开发者对 kafka 不是特别了解所导致的。这也是为什么要特意来学习 kafka 的原因,在后面的学习中,我们也会慢慢地来逐一来看我工作时曾遇到的各种问题。
1.2 Kafka Events
Apache Kafka 是 event streaming platform,以Event作为基础。Event的模型是key-pair对,以字节序列的方式存储在kafka服务器中。
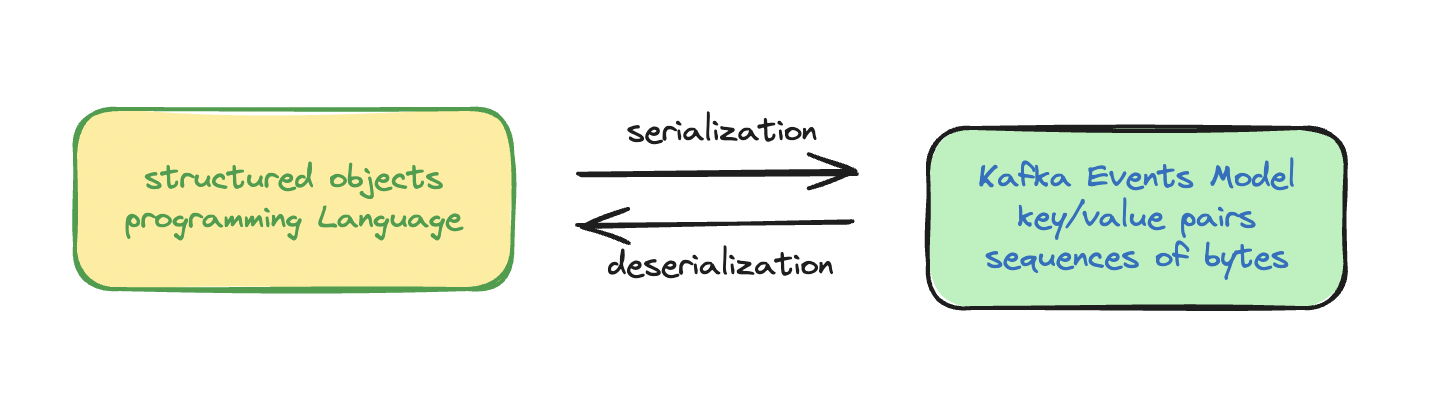
序列化和反序列化的方式有:JSON, JSON Schema, Avro, or Protobuf.
1.3 Topics

叫 topic 就是为了凸显自己想要展示的内容是什么。
有人说 topic 是一个 queue,但实际上准确来说,它更是log,log of events。
- Append only 只能像日志一样在后面插入
- Can only seek by offset, ont index 只能通过偏移量来查找
理解了 Kafka 的 topic 是一个log和log的特点就能更好地理解偏移量了。
1.4 Partitioning
Kafka is able to partition topics.
虽然有了副本机制可以保证数据的持久化或消息不丢失,但没有解决伸缩性的问题。伸缩性即所谓的 Scalability,是分布式系统中非常重要且必须要谨慎对待的问题。
什么是伸缩性呢?我们拿副本来说,虽然现在有了领导者副本和追随者副本,但倘若领导者副本积累了太多的数据以至于单台 Broker 机器都无法容纳了,此时应该怎么办呢?
一个很自然的想法就是,能否把数据分割成多份保存在不同的 Broker(或者叫做node和machine) 上?如果你就是这么想的,那么恭喜你,Kafka 就是这么设计的。这种机制就是所谓的分区(Partitioning)。

如果你了解其他分布式系统,你可能听说过分片、分区域等提法,比如 MongoDB 和 Elasticsearch 中的 Sharding、HBase 中的 Region,其实它们都是相同的原理,只是 Partitioning 是最标准的名称。
在创建一个topic 的时候就需要指定该 topic 需要几个副本和分区。
正是因为partition的存在导致Event的顺序无法保证,这不是queue的特性,从而叫做topic。
如何确定一条消息到哪个partition呢?
Partition is determined by key. 还记得么, Events 模型是 Key-Value Pairs。


根据key的不同划分到了不同的partitions,基于hash的算法来进行划分。
当没有Key的时候,key是null的时候,会依次循环向不同的partition中写入,保持均衡(evenly)。
1.5 Client & Server
客户端 (Client)
- 生产者(producer ,消息发送方)
- 消费者(consumer,消息接收方)
注意这里生产者和消费者都属于是 kafka 引擎的使用方,所以叫做客户端。
服务端 (Server):Kafka 集群(Cluster),由称为 Broker 的多个服务进程构成。
在 Kafka 中,发布订阅的对象是主题(Topic),你可以为每个业务、每个应用甚至是每类数据都创建专属的主题。
作为一名开发人员可能跟 producer 和 consumer 打交道更多,如果是一个运维人员可能就更加关注 broker 了。
1.6 Distributed Brokers
Kafka is composed of a network of machines called brokers.
Kafka 的服务器端由被称为 Broker 的服务进程构成,即一个 Kafka 集群由多个 Broker 组成.
Broker 负责接收和处理客户端发送过来的请求,以及对Event进行 partition 和 replicate。
虽然多个 Broker 进程能够运行在同一台机器上,但更常见的做法是将不同的 Broker 分散运行在不同的机器上,这样如果集群中某一台机器宕机,即使在它上面运行的所有 Broker 进程都挂掉了,其他机器上的 Broker 也依然能够对外提供服务。
这其实就是 Kafka 提供高可用的手段之一。
Broker 功能很简单,它很容易被 Scale 扩展。
一个Broker会负责相应的partitionsd的管理。

1.7 Replication 机制
实现高可用的另一个手段就是备份机制(Replication)。
备份的思想很简单,就是把相同的数据拷贝到多台机器上,而这些相同的数据拷贝在 Kafka 中被称为副本(Replicas)。
Kafka 定义了两类副本:
- 领导者副本(Leader Replicas)前者对外提供服务,这里的对外指的是与客户端程序进行交互
- 追随者副本(Follower Replicas)。而后者只是被动地追随领导者副本而已,不能与外界进行交互。
当向leader写入数据时,追随者会自动完成replicate的工作。
当然了,你可能知道在很多其他系统中追随者副本是可以对外提供服务的,比如 MySQL 的从库是可以处理读操作的,但是在 Kafka 中追随者副本不会对外提供服务。
对了,一个有意思的事情是现在已经不提倡使用 Master-Slave 来指代这种主从关系了,毕竟 Slave 有奴隶的意思,在美国这种严禁种族歧视的国度,这种表述有点政治不正确了,所以目前大部分的系统都改成 Leader-Follower 了。
1.8 Producer
生产者在发送消息的时候,实际上并不是逐一发送的,而是放在缓存中积累到一定程度批量发送,从而提高效率: Records Accumulated Into Record Batches.
Sending each record as itself is not going to be efficient, because it has too much overhead.

在producer端看消息发送实际上是这样的:

批量发送消息的时机
消息的发送明面上是one by one,但实际上却是先放在Buffer中等待批量发送(经压缩后),那batch的发送的时机就很重要,什么时候进行真正的send呢?
由两个因素决定,一个是根据时间(time),一个是根据大小(batch size)。
linger.ms每当过了这段时间,就会触发发送。batch.size指定了一个批次可以使用的内存大小,按照字节数计算(而不是消息个数),每当批次的大小到达这个大小就会触发发送。
如果使用Spring kafka,可以在producer下进行linger.ms和batch.size的属性设置:
spring.kafka.producer.properties.linger.ms=5000
spring.kafka.producer.batch.size=500
Send的阻塞
上图中展示了在producer端,记录发送的逻辑,思考一个问题,如果Buffer的内存资源耗尽了怎么办?
当缓冲池的内存块用完后,消息追加调用将会被阻塞,直到有空闲的内存块。从而会造成阻塞。
当 linger.ms 和 batch.size 设置得足够大,用户发送消息的速度又比较快时,出buffer数据的速率会小于进buffer数据的速率,从而就是会造成 buffer 的空间不足。
当Kafka集群压力比较大的时候,broker处理send请求会变慢,此时也会造成Buffer空间不足。
相关的配置:
spring.kafka.producer.buffer-memory=33554432
参考文章:异步发送消息也会阻塞?
1.9 Consumer

一个topic可以由多个消费者读取。
而如果增加某个consumer的实例时,实例会从分配的partition中读取event。如图示:

通过改变消费者实例数量,就会导致partition的重新分配,这一过程叫做 Rebalance 重平衡。
注意,如果有个N个partition,但却有N+M个consumer,那么多出来的M个consumer是不会消费消息的。
1.10 Offset
消息位移
生产者向分区写入消息,每条消息在分区中的位置信息由一个叫位移(Offset)的数据来表征。分区位移总是从 0 开始,假设一个生产者向一个空分区写入了 10 条消息,那么这 10 条消息的位移依次是 0、1、2、......、9。
消费者位移
Consumer Offset。表征消费者消费进度,每个消费者都有自己的消费者位移。
后面我们还会经常跟 Offset 打交道。它是我们用来看消息发送成功与否和消费是否阻塞的重要信息。
二、深入 Kafka Cluster
2.1 Overview of Kafka Architecture

这里的Kafka Connect、Kafka Stream和Ksql暂时不是学习的重点,当前(2024年)我们只学习Storage Layer的两个接口实现:
- Producer APIs
- Consumer APIs
2.2 Broker
Broker中需要处理两个特别重要的Request请求,一个是Producer端的send record请求,一个consumer端的consume record请求。
Produce Request 的处理过程

当需要进行replicate的时候,就需要把消息放在Purgatory中,不占用I/O线程。
Fetch Request 的处理过程
消费者拿消息的过程和上面差不多。
2.3 Replication Protocol

ISRs
Cilents 只和leader broker进行读写,其他followers跟随leader,由follower主动拉取leader的日志进行同步的完成复制,这叫做同步副本:in-sync replicas (ISRs)。
Kafka的副本策略称为ISRs(in-sync replicas),动态维护了一个包含所有已提交日志的节点集合,通过zookeeper存储该集合,并由zookeeper从集合中选出一个节点作为leader,日志会先写入到leader,再由ISRs中的其他follower节点主动进行复制同步。
High Watermark
高水位(High Watermark,HW)并不是什么高深的概念,表示已经提交(committed)的最大日志偏移量。
Kafka中某条日志“已提交(committed)”的意思是ISRs中所有节点都包含了此条日志。
对于ack设置为all的producer的一条写请求,leader会等到ISRs中的所有follower都拉取到此条日志后才会更新自己的HW,同时回复给producer写成功。
对应的spring kafka配置:
spring.kafka.producer.acks=all
acks的值为0,1和-1或者all。
- 0表示
Producer往集群发送数据不需要等到集群的返回,不确保消息发送成功。安全性最低但是效率最高。- 1表示
Producer往集群发送数据只要Leader成功写入消息就可以发送下一条,只确保Leader接收成功。- -1 或 all表示
Producer往集群发送数据需要所有的ISR Follower都完成从Leader的同步才会发送下一条,确保Leader发送成功和所有的副本都成功接收。安全性最高,但是效率最低。
如何确认Fellowers都接受到了Records

通过 Leader 发出的 FetchRequest, 只有提交了的(committed)的records才会被消费者所感知。
The way we model the committed records is through this concept called high watermark.
Epoch
Kafka 中还有一个重要的概念叫做 epoch: Kafka中的epoch是什么?
// todo 这个对我还说有点困难,难以理解。
二、分区策略
所谓分区策略是决定生产者将消息发送到哪个分区的算法。Kafka 为我们提供了默认的分区策略,同时它也支持你自定义分区策略。
如果要自定义分区策略,你需要显式地配置生产者端的参数 partitioner.class 。这个参数该怎么设定呢?方法很简单,在编写生产者程序时,你可以编写一个具体的类实现org.apache.kafka.clients.producer.Partitioner接口。这个接口也很简单,只定义了两个方法:partition() 和 close(),通常你只需要实现最重要的 partition 方法。我们来看看这个方法的方法签名:
int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster);
这里的topic、key、keyBytes、value和valueBytes都属于消息数据,cluster则是集群信息(比如当前 Kafka 集群共有多少主题、多少 Broker 等)。Kafka 给你这么多信息,就是希望让你能够充分地利用这些信息对消息进行分区,计算出它要被发送到哪个分区中。只要你自己的实现类定义好了 partition 方法,同时设置partitioner.class参数为你自己实现类的 Full Qualified Name,那么生产者程序就会按照你的代码逻辑对消息进行分区。虽说可以有无数种分区的可能,但比较常见的分区策略也就那么几种,下面我来详细介绍一下。
在Spirng - kakfa中,我们可以在发送消息时直接指定 partition。
如果不做任何指定,那么 kafka 是如何确定一个消息该发往哪个分区的呢?
轮询策略
也称 Round-robin 策略,即顺序分配。比如一个主题下有 3 个分区,那么第一条消息被发送到分区 0,第二条被发送到分区 1,第三条被发送到分区 2,以此类推。当生产第 4 条消息时又会重新开始,即将其分配到分区 0,就像下面这张图展示的那样。
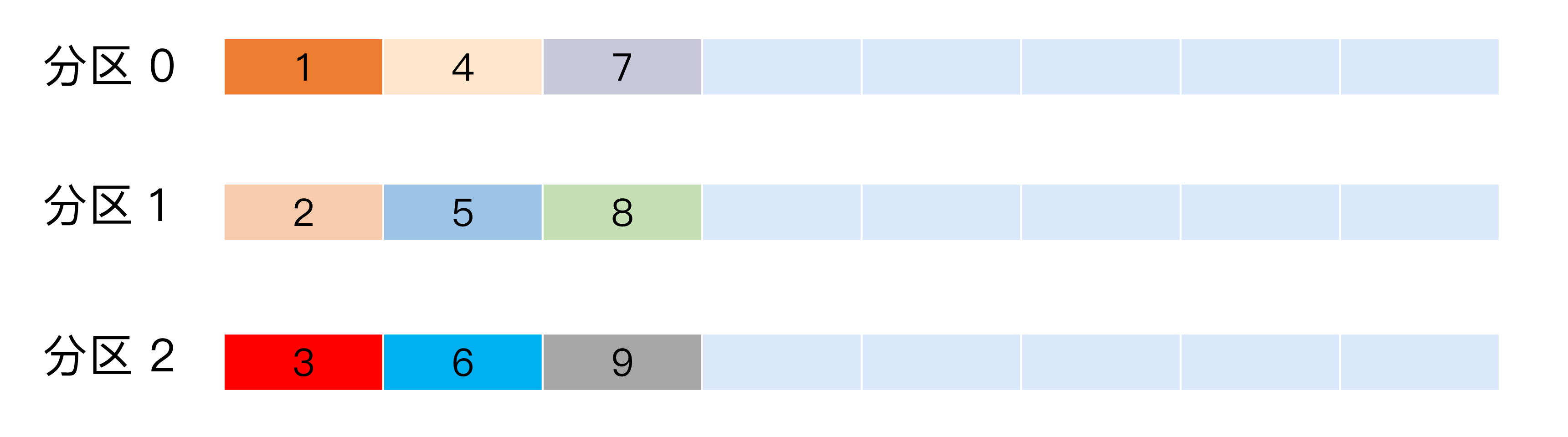
这就是所谓的轮询策略。轮询策略是 Kafka Java 生产者 API 默认提供的分区策略。如果你未指定 partitioner.class 参数,那么你的生产者程序会按照轮询的方式在主题的所有分区间均匀地“码放”消息。
轮询策略有非常优秀的负载均衡表现,它总是能保证消息最大限度地被平均分配到所有分区上,故默认情况下它是最合理的分区策略,也是我们最常用的分区策略之一。
随机策略
也称 Randomness 策略。所谓随机就是我们随意地将消息放置到任意一个分区上,如下面这张图所示。
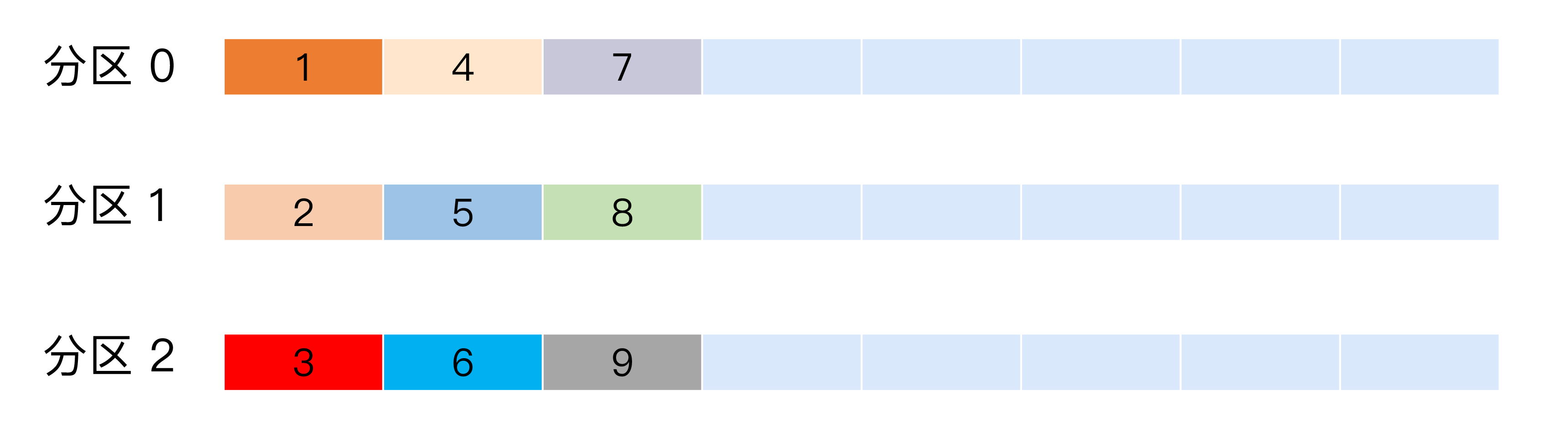
如果要实现随机策略版的 partition 方法,很简单,只需要两行代码即可:
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return ThreadLocalRandom.current().nextInt(partitions.size());
先计算出该主题总的分区数,然后随机地返回一个小于它的正整数。本质上看随机策略也是力求将数据均匀地打散到各个分区,但从实际表现来看,它要逊于轮询策略,所以如果追求数据的均匀分布,还是使用轮询策略比较好。事实上,随机策略是老版本生产者使用的分区策略,在新版本中已经改为轮询了。
按消息key保存策略
也称 Key-ordering 策略。有点尴尬的是,这个名词是我自己编的,Kafka 官网上并无这样的提法。Kafka 允许为每条消息定义消息键,简称为 Key。这个 Key 的作用非常大,它可以是一个有着明确业务含义的字符串,比如客户代码、部门编号或是业务 ID 等;也可以用来表征消息元数据。特别是在 Kafka 不支持时间戳的年代,在一些场景中,工程师们都是直接将消息创建时间封装进 Key 里面的。一旦消息被定义了 Key,那么你就可以保证同一个 Key 的所有消息都进入到相同的分区里面,由于每个分区下的消息处理都是有顺序的,故这个策略被称为按消息键保序策略。
实现这个策略的 partition 方法同样简单,只需要下面两行代码即可:
List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);
return Math.abs(key.hashCode()) % partitions.size();
前面提到的 Kafka 默认分区策略实际上同时实现了两种策略:如果指定了 Key,那么默认实现按消息键保序策略;如果没有指定 Key,则使用轮询策略。
三、Kafka 消息发不出去?
3.1 send 方法,同步or异步
在使用了 Spring-Kafka 的 Spring 工程中来发送一条 kafka 消息十分简单,我们会使用 Spring 帮忙封装好的 KafkaTemplate 来发送消息。
Spring 在帮忙接入其他第三方组件/服务的时候一般都会提供一个 template 来方便开发者使用这些第三方组件/服务,比如 redis、elastic search 都有相应的 template。
kafka 对应的 template 叫做 KafkaTemplate,位于 org.springframework.kafka.core 包中。
KafkaTmeplate 对发送消息的同步很简单,只需要调用相应的 send() 方法即可。
ListenableFuture<SendResult<K, V>> sendDefault(V var1);
……
ListenableFuture<SendResult<K, V>> send(String var1, V var2);
ListenableFuture<SendResult<K, V>> send(String var1, K var2, V var3);
……
ListenableFuture<SendResult<K, V>> send(ProducerRecord<K, V> var1);
ListenableFuture<SendResult<K, V>> send(Message<?> var1);
而 kafka 底层提供的 send 方法有异步的,还有可以同步的。
org.apache.kafka.clients.producer.Producer 中:
Future<RecordMetadata> send(ProducerRecord<K, V> var1);
Future<RecordMetadata> send(ProducerRecord<K, V> var1, Callback var2);
kafkaTemplate 中所有 send 方法最后发送消息时调用的都是org.apache.kafka.clients.producer.Producer中第二个 send 方法。
Future<RecordMetadata> sendFuture = producer.send(producerRecord, this.buildCallback(producerRecord, producer, future, sample));
返回 ListenableFuture 来控制是否同步和异步:
- 异步发送:
kafkaTemplate.send(topic,message);
- 同步发送:
kafkaTemplate.send(topic,message).get();
发送消息,Future的get()方法会一直阻塞,一直到当前线程获取到返回值,也就是消息发送成功了。
所以,避免消息丢失的第一点:
尽量使用同步方法,而非异步方法,从而确保消息确实发送成功或者发送失败。
3.2 巧妙配置 producer 的参数
3.2.1 消息发送重试次数
kafka 客户端与服务端通信肯定是走网络的,所有短暂有巧合的网络通信也可能导致消息发送失败,我们可以设置一个重试次数的参数,当参数的值大于0时,发送消息失败时就会进行重试,要么发送成功要么继续重试直到达到最大重试次数。
在 spring-kafka 中可以很简单的设置此参数:
spring.kafka.producer.retries = 1
故当出现网络等原因导致偶然性的发送失败,最好的解决办法就是通过 kafka 自带的重试机制来进行消息重发。
- 设置 acks = all。acks 是 Producer 的一个参数,代表了你对“已提交”消息的定义。如果设置成 all,则表明所有副本 Broker 都要接收到消息,该消息才算是“已提交”。这是最高等级的“已提交”定义。
- 设置 unclean.leader.election.enable = false。这是 Broker 端的参数,它控制的是哪些 Broker 有资格竞选分区的 Leader。如果一个 Broker 落后原先的 Leader 太多,那么它一旦成为新的 Leader,必然会造成消息的丢失。故一般都要将该参数设置成 false,即不允许这种情况的发生。
- 设置 replication.factor >= 3。这也是 Broker 端的参数。其实这里想表述的是,最好将消息多保存几份,毕竟目前防止消息丢失的主要机制就是冗余。
- 设置 min.insync.replicas > 1。这依然是 Broker 端参数,控制的是消息至少要被写入到多少个副本才算是“已提交”。设置成大于 1 可以提升消息持久性。在实际环境中千万不要使用默认值 1。
- 确保 replication.factor > min.insync.replicas。如果两者相等,那么只要有一个副本挂机,整个分区就无法正常工作了。我们不仅要改善消息的持久性,防止数据丢失,还要在不降低可用性的基础上完成。推荐设置成 replication.factor = min.insync.replicas + 1。
- 确保消息消费完成再提交。Consumer 端有个参数 enable.auto.commit,最好把它设置成 false,并采用手动提交位移的方式。就像前面说的,这对于单 Consumer 多线程处理的场景而言是至关重要的。
附录
连接Kafka Server 的工具
IDEA 上的 kafkalytic 插件
IDEA 的bigtools插件
Docker 搭建 kafka
在学习的时候自然需要一个 kafka 集群来提供 kafka 服务端,这个集群我们可以搭建在自己手边的物理机或者云服务器上,为了方便,将其部署在 docker 上是一个很好的方式。
接下来就给出我的部署方法。
因操作系统或者 docker 版本问题,按照此方法一步步执行的过程中可能会遇到一些小坑,本人环境:
- 物理机:Macbook 2021 m1、Vertura 系统 Version 13.0。
- Docker 版本:Mac 桌面版 Docker version 20.10.17
教程中不含 如何下载docker、Spring boot 等基础内容。
下载镜像
docker pull wurstmeister/zookeeper
docker pull wurstmeister/kakfa
wurstmeister 是镜像网站中 关于 kafka 镜像使用最多的一个镜像,直接 pull,默认最新版本。 我们选择最常用的 zookeeper 作为 kafka 的注册中心。
命令行方式启动 zookeeper 和 kafka
kafka 集群是依赖 zookeeper 注册中心的,要先启动 zookeper。
docker run -d --name zookeeper --publish 2181:2181 --volume /etc/localtime:/etc/localtime wurstmeister/zookeeper
启动 kafka:
docker run -d --name kafka --publish 9092:9092 \
--link zookeeper \
--env KAFKA_ZOOKEEPER_CONNECT={ip}:2181 \
--env KAFKA_ADVERTISED_HOST_NAME={ip} \
--env KAFKA_ADVERTISED_PORT=9092 \
--volume /etc/localtime:/etc/localtime \
wurstmeister/kafka:latest
其中 ip 是物理机 ip 地址,可以使用 127.0.0.1 的本地 ip 试一下, 如果不好使可以换成网络 ip 试试。
我的部署环境中部署时使用127的本地ip就不好使,使用
ipconfig(Linux 系统命令)查看 ip 地址换上去即可。
好久之后遇到的问题:
https://github.com/confluentinc/cp-docker-images/issues/801 这个是真的好使:
The following chunk of code might help you in running zookeeper as well as kafka successfully.
Start the zookeeper
docker run --name=zookeeper -d -e ZOOKEEPER_CLIENT_PORT=2181 -p 2181:2181 -p 2888:2888 -p 3888:3888 confluentinc/cp-zookeeper:latest
Fetch the zookeeper's container IP
Zookeeper_Server_IP=$(docker inspect zookeeper --format='{{ .NetworkSettings.IPAddress }}')
Start the Kafka server
docker run --name=kafka -e KAFKA_ZOOKEEPER_CONNECT=${Zookeeper_Server_IP}:2181 -e KAFKA_LISTENERS=PLAINTEXT://localhost:9092 -d -p 9092:9092 confluentinc/cp-kafka:latest
只要不报错就一般没问题了,进入容器后就可以进行相应 kafka 操作了。
docker exec -it {container id} /bin/bash
如果还是启动失败,可以试试这样(chatGpt给出的建议): 检查Zookeeper和Kafka容器是否在同一个Docker网络中,并且可以采取必要的步骤来确保它们在同一个网络中。
# 创建一个网络
docker network create zookeeper_kafka
# 将Zookeeper和Kafka容器连接到同一个网络 后面是容器id
docker network connect zookeeper_kafka 4a9c8f8d6c68
docker network connect zookeeper_kafka 85bc084c0954
Spring Boot 连接本地 kafka
这个非常简单,只要引入了Spring kafka 依赖,配置文件中确定了 ip + port 就可以。
值得注意的是,尽可能要保持 spring-kafka 和 Spring Boot 的版本对应,否则可能会出现一些不必要的麻烦,我使用的是2.5.3 的 boot 和 2.7.4 spring-kafka。
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
spring:
kafka:
consumer:
enable-auto-commit: false
auto-commit-interval: 100
auto-offset-reset: earliest
max-poll-records: 500
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
properties:
sasl.mechanism: PLAIN
security.protocol: PLAINTEXT
#如果在这个时间内没有收到心跳,该消费者会被踢出组并触发{组再平衡 re balance}
session.timeout.ms: 60000
producer:
retries: 1 #若设置大于0的值,客户端会将发送失败的记录重新发送
batch-size: 500
buffer-memory: 33554 #Producer 用来缓冲等待被发送到服务器的记录的总字节数,33554432是缺省配置
key-serializer: org.apache.kafka.common.serialization.StringSerializer #关键字的序列化类
value-serializer: org.apache.kafka.common.serialization.StringSerializer #值的序列化类
properties:
sasl.mechanism: PLAIN
security.protocol: PLAINTEXT
delivery.timeout.ms: 20000 # 20s
request.timeout.ms: 10000 # 10s
linger.ms: 5000
listener:
ack-mode: manual_immediate
poll-timeout: 500S
bootstrap-servers: 127.0.0.1:9092
问题积累:
Q:老师,今天才学习到这篇文章,还是老师能够在百忙之中抽出时间来解答我的困惑。 这篇文章提到了消息的协议,老师这里介绍了两种模式一种是点对点,一种是订阅,发布模式。但是,为什么我一开始想到消息的协议是http之类的传输协议?这两个有什么区别和联系?
A: http不属于消息传输协议,它是网络通信协议的一种,严格来说这是两个范畴或者说是两个层次上的协议。
通常来说,两个进程进行数据流交互的方式一般有三种:
- 通过数据库:进程1写入数据库;进程2读取数据库
- 通过服务调用:比如REST或RPC,而HTTP协议通常就作为REST方式的底层通讯协议
- 通过消息传递的方式:进程1发送消息给名为broker的中间件,然后进程2从该broker中读取消息。消息传输协议属于这种模式。
因此我说虽然我们都称它们为协议,但它们不是一个层次上的协议。
Q:请思考一下为什么 Kafka 不像 MySQL 那样允许追随者副本对外提供读服务?
A:作者:huxihx 链接:https://www.zhihu.com/question/327925275/answer/705690755 来源:知乎
主从分离与否没有绝对的优劣,它仅仅是一种架构设计,各自有适用的场景。
Redis和MySQL都支持主从读写分离,我个人觉得这和它们的使用场景有关。对于那种读操作很多而写操作相对不频繁的负载类型而言,采用读写分离是非常不错的方案——我们可以添加很多follower横向扩展,提升读操作性能。反观Kafka,它的主要场景还是在消息引擎而不是以数据存储的方式对外提供读服务,通常涉及频繁地生产消息和消费消息,这不属于典型的读多写少场景,因此读写分离方案在这个场景下并不太适合。
第三、Kafka副本机制使用的是异步消息拉取,因此存在leader和follower之间的不一致性。如果要采用读写分离,必然要处理副本lag引入的一致性问题,比如如何实现read-your-writes、如何保证单调读(monotonic reads)以及处理消息因果顺序颠倒的问题。相反地,如果不采用读写分离,所有客户端读写请求都只在Leader上处理也就没有这些问题了——当然最后全局消息顺序颠倒的问题在Kafka中依然存在,常见的解决办法是使用单分区,其他的方案还有version vector,但是目前Kafka没有提供。
最后、社区正在考虑引入适度的读写分离方案,比如允许某些指定的follower副本(主要是为了考虑地理相近性)可以对外提供读服务。当然目前这个方案还在讨论中。
Q:聊聊Kafka的版本号
https://time.geekbang.org/column/article/100726
Q:Kafka线上集群部署方案怎么做:
https://time.geekbang.org/column/article/101107
📔Content
- 一、Kafka 基础
- 1.1 Kafka 与 消息引擎
- 1.2 Kafka Events
- 1.3 Topics
- 1.4 Partitioning
- 1.5 Client & Server
- 1.6 Distributed Brokers
- 1.7 Replication 机制
- 1.8 Producer
- 批量发送消息的时机
- Send的阻塞
- 1.9 Consumer
- 1.10 Offset
- 消息位移
- 消费者位移
- 二、深入 Kafka Cluster
- 2.1 Overview of Kafka Architecture
- 2.2 Broker
- Produce Request 的处理过程
- Fetch Request 的处理过程
- 2.3 Replication Protocol
- ISRs
- High Watermark
- 如何确认Fellowers都接受到了Records
- Epoch
- 二、分区策略
- 轮询策略
- 随机策略
- 按消息key保存策略
- 三、Kafka 消息发不出去?
- 3.1 send 方法,同步or异步
- 3.2 巧妙配置 producer 的参数
- 3.2.1 消息发送重试次数
- 附录
- 连接Kafka Server 的工具
- IDEA 上的 kafkalytic 插件
- IDEA 的bigtools插件
- Docker 搭建 kafka
- 下载镜像
- 命令行方式启动 zookeeper 和 kafka
- Spring Boot 连接本地 kafka
- 问题积累:

